In this post I want to share some thoughts about Domain-Driven Design (DDD) and retrieving the data aggregated from multiple tables or documents while using a Repository pattern in your project. Sometimes the data structure needed does not fit any of the entities your Repository can return.
How to deal with this and what possible solutions apply is the focus of today’s post.
Many development teams are asking this question. It often pops up when there is a need to build a report or do some data analysis.
This question’s answer could be pretty straightforward once conceptual issues are clarified.
As a starting point, let’s quickly see what a Repository pattern in Domain-Driven Design means. The Repository implements a layer to retrieve an entity from the data storage or persist/delete an object.
For our purpose, let’s describe a simple collaborative Project Delivery Platform scenario, where multiple Contributors can join a Project over some Invitation. The corresponding Class Diagram may look like the one below. The simplified model is similar to one from the projects we do at CQUELLE.
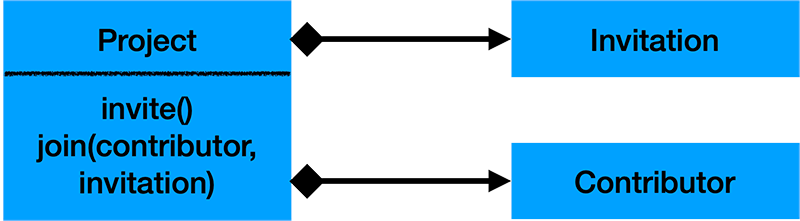
As we see from the Diagram, a Project entity might contain multiple Invitations and multiple Contributors. There are two methods to generate a new Invitation and add a Contributor to the project.
Our goal would be to generate a report listing the total number of projects each Contributor has.
Generating this kind of data through ProjectRepository might be slow if the system has many projects and contributors, especially if the model is larger than the one above created for illustration purposes.
There is one crucial point here. There should be only one Repository per Root Aggregate within a given Bounded Context as far as we speak about Domain-Driven Design, not multiple. In our case, this is ProjectRepository, which returns a Project or many Projects. Over each given Project, we can navigate to the data needed – to the Contributor.
The scenario above is precisely the illustration of how it’s going to be time-consuming and needs another way to solve it.
Any attempt to create additional repositories for Contributor or some other new entity contradicts Domain-Driven Design principles; this is the most typical mistake I’ve seen in multiple teams.
A slightly better approach mentioned very often on the Internet is the so-called Command-Query Separation Principle (CQSP). That could be a potential solution, but CQSP is a different competitor paradigm. Implementing it within Domain-Driven Design Solution would open two doors of manipulating an object’s state and, therefore, breaching the design.
The cleanest way of solving the problem is thinking further and adjusting the model design to describe reality naturally.
If finding a model fitting naturally could not be done, an alternative solution within Domain-Driven Design would be creating a service. The service does not change the model’s state and does nothing else than querying the database and returning the data in the necessary format. I call it Query Separation Service (QSS) if we parallel to CQSP.
As with any service in Domain-Driven Design, it’s a back door of possible misuse; I encourage you to try hard to fit the model naturally first, otherwise keep an eye on how the service’s outcome consumed further.
I wish you happy coding and clean model along the way.
Take Care,
Ievgen